Advanced memory allocation
OS_Mop variations
During memory pool opening, options settings select scheme of allocation. All flags are OR-combined in A.
Default, one bank memory pool
MM_S0 to MM_S3 select the desired segment. MM_S1 is the simplest and fastest according OZ design.
If no other bit is set, then OZ will allocate in one of the most free bank. This allocation scheme is fast and reserved for up to 16K needs. All memory allocated from that pool is guaranteed to be in same bank.
It is recommended for allocation of chunks (<255 bytes allocation). An RC_Room error returned by OS_Mal will just mean that this pool is exhausted (bank is full). A subsequent OS_Mop will open a new pool from the most free bank. If an RC_Room is returned, then the whole memory is full.
Multiple banks (MM_MUL)
When MM_MUL flag is set, the pool is allocated anywhere in the free memory. It begins by the latest bank in the order of slot 1-2-3-0.
This method has some overhead to find and add new free page. The MM_FIX flag can be set in combination with MM_MUL. It avoids allocation in the swap area used for bad or ugly application. It will reduce overhead of the page reshuffling when entering/exiting such applications.
This allocation scheme is recommended for page allocation (256 bytes). This flag is mandatory for block allocation or explicit allocation. It is recommended for data storage in good applications. This option is used by the filesystem pool or the system process pool.
Exclusive banks (MM_EXC)
This allocation scheme will allocate free banks in priority to the pool. It is as fast as the default scheme but not limited to one bank. Each time a bank is full, the next allocated is the most free available. This scheme is recommended for allocation of a huge number of chunks or pages that will be quickly released. Usage in a popdown or a shell command is a good rule. It It has the disadvantage to induce more memory fragmentation. This allocation method has been implemented in OZ 5.0.
Slot/bank selection (MM_SLT)
Usage of this option is not recommended and should never be used. System itself never use it. When MM_SLT is set in A, C register holds the slot (MC_CI...) or the bank number ($20-$FF).
OS_Mal variations
OS_Mal behaves differently according the amount of memory requested in BC. OS_Mal does not bind bank but always adjust HL to the desired segment. A should always be zero.
Page
The fastest allocation is performed for a page (BC=256). For example, filesystem allocates pages and divide them is 4 sectors of 62 bytes.
Chunk
When allocating chunks (up to 253 bytes), memory area returned from OS_Mal is guaranteed to be in single page. Chunk allocation has overhead required to manage the page filling. Notice that when BC=254, only 253 bytes are given back. And when 255 bytes are requested, a full page is given.
Block
A block of page can be allocated up to 16K. MM_MUL should have been set during pool opening by OS_Mop. Notice that when 257 bytes are requested, 512 bytes (2 consecutive pages) are allocated. Block allocation has been implemented since OZ 4.7 thanks to the explicit memory allocation introduced in OZ 4.6.
Slot selection
OS_Mal should always be called with A=0. Usage of this option is not recommended and should never be used. When MM_MUL was set during pool opening in OS_Mop, slot selection of allocation can be forced by setting slot number in A (1-3) ORed with MA_SLT.
Allocation internals
Chunk and page allocation begins from the latest bank of the slot and goes downward. Block allocation begins at the first bank and goes upward. It avoids fragmentation (big blocks inside the file system). In the same principle, MM_EXC forces in priority most free banks and MM_MUL fills the slot downward. Memory allocation for the AZ module assembler is a good example, I performed some tests.
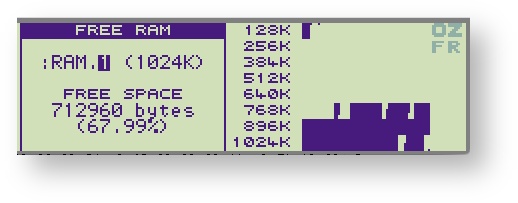
In the first example, it allocates chunks using MM_MUL option. Those chunks are allocated and released during page allocation for the file system. It ends with a fragmented filesystem.
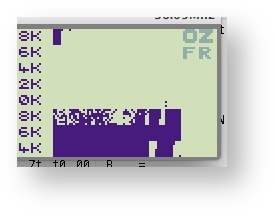
In the second image, MM_EXC was specified. Banks allocated for chunks were less mixed with the filesystem. Result is a really decreased fragmentation and a better overall performance (around 10% of time).